Jeopardy! is in the finals of its Battle of the Decades, with Brad Rutter, Ken Jennings, and Roger Craig squaring off. The players have ridiculous résumés. Brad is the all-time Jeopardy! king, having never lost to a human and racking up $3 million in the process. Ken has won more games than anyone else. And Roger has the single-day earnings record.
That sets the scene for the middle of Double Jeopardy. Roger had accumulated a modest lead through the course of play and hit a Daily Double. He then made the riskiest play possible–he wagered everything. The plan backfired, and he lost all of his money. He was in the negatives by the end of the round and had to sit out of Final Jeopardy.
Did we witness the dumbest play in the history of Jeopardy? I don’t think so–Roger’s play actually demonstrated quite a bit of savvy. Although Roger is a phenomenal player, Brad and Ken are leaps and bounds better than everyone else. (And Brad might be leaps and bounds better than Ken as well.) If Roger had made a safe wager, Brad and Ken would have likely eventually marched past his score as time went on–they are the best for a reason, after all. So safe wagers aren’t likely to win. Neither is wagering everything and getting it wrong. But wagering everything and getting it right would have given him a fighting chance. He just got unlucky.
All too often, weaker Jeopardy! players make all the safest plays in the world, doing everything they can to keep themselves from losing immediately. They are like football coaches who bring in the punting unit down 10 with five minutes left in the fourth. Yes, punting is safe. Yes, punting will keep you from outright losing in the next two minutes. But there is little difference between losing now and losing by the end of the game. If there is only one chance to win–to go for it on fourth down–you have to take it. And if there is only one way to beat Brad and Ken–to bet it all on a Daily Double and hope for the best–you have to make it a true Daily Double.
Edit: Roger Craig pretty much explicitly said that this was the reason for his Daily Double strategy on the following night’s episode. Also, this “truncated punishment” mechanism also has real world consequences, such as the start of war.
Edit #2: Julia Collins in the midst of an impressive run, having won 14 times (the third most consecutive games of all time) and earned more money than any other woman in regular play. She is also fortunate that many of her opponents are doing very dumb things like betting $1000 on a Daily Double that desperately needs to be a true Daily Double. People did the same thing during Ken Jennings’ run, and it is mindbogglingly painful to watch.
Here is a bad research design I see way too frequently.* The author presents a model. The model shows that if sufficient amounts of x exist, then y follows. The author then provides a case study, showing that x existed and y occurred. Done.
Do you see the problem there? I removed “sufficient” as a qualifier for x from one sentence to the next. Unfortunately, by doing so, I have made the case study worthless. In fact, such case studies often undermine the exact point the author was trying to make with the model!
Let me illustrate my point with the following (intentionally ridiculous) example. Consider the standard bargaining model of war. State A and State B are in negotiations. If bargaining breaks down, A prevails militarily and takes the entire good the parties are bargaining over with probability p_A; B prevails with complementary probability, or 1 – p_A. War is costly, however; states pay respective costs c_A and c_B > 0.
That is the standard model. Now let me spice it up. One thing that the model does not consider is the cost of the stationery**, ink, and paper necessary to sign a peaceful agreement. Let’s call that cost s, and let’s suppose (without loss of generality) that state A necessarily pays the stationery costs.
Can the parties reach a peaceful agreement? Well, let x be A’s share of a peaceful settlement. A prefers a settlement if it pays more than war, or x – s > p_A – c_A. We can rewrite this as x > p_A – c_A + s.
Meanwhile, B prefers a settlement if the remainder pays better than war, or 1 – x > 1 – p_A – c_B. This reduces to x < p_A + c_B.
Stringing these inequalities together, mutually preferable peaceful settlements exist if p_A – c_A + s < x < p_A + c_B. In turn, such an x exists if s < c_A + c_B.
Nice! I have found a new rationalist explanation for war! You see, if the costs of stationery exceed the costs of war (or s > c_A + c_B), at least one state would always prefer war to peace. Thus, peace is unsustainable.
Of course, my argument is completely ridiculous–stationery does not cost that much. My theory remains valid, it just lacks empirical plausibility.
And, yet, formal theorists too often fail to substantively interpret their cutpoints in this way. That is, they do not ask if real-life parameters could ever sustain the conditions necessary to lead to the behavior described.
Instead, you will get case studies that look like the following:
I presented a model that shows that the costs of stationery can lead to war. In analyzing the historical record of World War I, it becomes clear that the stationery of the bargained resolution would have been very expensive, as the ball point pen had only been invented 25 years ago and was still prohibitively costly. Thus, World War I started.
Completely ridiculous! And, in fact, the case study demonstrated the opposite of what the author had intended. That is, if you actually analyze the cutpoint, you will see that the cost of stationery was much lower than the costs of war, and thus the cost of stationery (at best) had a negligible causal connection to the conflict.
In sum, please, please interpret your cutpoints. Your model only provides useful insight if its parameters match what occurred in reality. It is not sufficient to say that cost existed; rather, you must show that the cost was sufficiently high (or low) compared to the other parameters of your model.
* This blog post is the result of presentations I observed at ISA and Midwest, though I have seen some published papers like this as well.
** I am resisting the urge to make this an infinite horizon model so I can solve for the stationary MPE of a stationery game.
TL;DR: The historic Palmer House Hilton elevators are terribly slow because of bad strategic design, not mechanical issues or overcrowding.
Midwest Political Science Association’s annual meeting–the largest gathering of political scientists–takes place at the historic* Palmer House Hilton each year. While the venue is nice, the elevator system is horrible. And with gatherings on the first eight floors, the routine gets old really fast.
Interestingly, though, the delays are not the result of an old elevator system or too many political scientists moving at once.** Rather, the problem is shoddy strategic thinking.
Each elevator bay has three walls. The elevators along each wall have different tasks. Here’s the first one:
Elevators on this floor go from the ground floor to the 12th floor.
Here’s the second:
These go from the ground floor to the eighth floor or the 18th floor to the 23rd floor.
And the last wall:
These go from the ground floor to the eighth floor and the 13th floor to the 17th.
Now suppose you are on the ground level want to go to the 7th floor. What’s the fastest way to get there? For most elevator systems, you press a single button. The system figures out which elevator will most efficiently take you there and dispatches that elevator to the ground level.
But historic Palmer House Hilton’s elevators are not a normal system. Each wall runs independent of one another with three separate buttons to press. So if you really want to get to the seventh floor as fast as possible, you have to press all three–after all, you do not know which of the three systems will most quickly deliver an elevator to your position.
Unfortunately, this has a pernicious effect. Once the first elevator arrives, the call order to the other two systems does not cancel. Thus, they will both (eventually) send an elevator to that floor. Often times, this means an elevator wastes a trip by going to the floor and picking no one up. In turn, people on other floors waiting for that elevator suffer some unnecessary delay.
This is why (1) the elevator system takes forever and (2) you often stop at various floors and pick up no one. We would all be better off if people limited their choice to a single system, but a political scientist running late to his or her next panel does not care about efficiency.
(Let this sink in for a moment. The largest gathering of political scientists has yet to overcome a collective action that plagues it on an every day basis.)
Given the floor restrictions for the elevators, the best solution I can think of would be to install an elevator system where you press the button of the floor you want outside the elevator, and the system chooses which to send from the three walls. This would be mildly inconvenient but would stop all the unnecessary elevator movements.
_____________
*Why is it historic? I have no clue. But everyone says it is.
**The latter undoubtedly contributes to the problem, however.
Arthur Chu, current four-day champion on Jeopardy!, has made a lot of waves around the blogosphere with his unusual play style. (Among other things, he hunts all over the board for Daily Doubles, has waged strange dollar amounts when getting one, and clicks loudly when ringing in.) What has garnered the most attention, though, is his determination to play for the draw. On three occasions, Arthur has had the opportunity to bet enough to eliminate his opponent from the show. Each time, he has bet enough so that if his opponent wagers everything, he or she will draw with Arthur.
It is worth noting that draws aren’t the worst thing in Jeopardy. Unlike just about all other game shows, there is no sudden death mechanism. Instead, both players “win” and become co-champions, keeping the money accumulated from that game and coming back to play again the next day. There is no cost to you as the player; Jeopardy! foots the bill.
Why is Arthur doing this? The links provided above give two reasons. First, there have been instances where betting $1 more than enough to force a draw has resulted in the leader ultimately losing the game. Betting more than the absolute minimum necessary to ensure that you get to stay the next day thus has some risks. Second, if your opponents know that you will bet to draw, it induces them to wager all of their money. This is advantageous to the leader in case everyone gets the clue wrong.
That second point might be a little complicated, so an example might help. Suppose the leader had $20,000, second place had $15,000, and third place died in the middle of the taping. If the leader wagers $10,000, second place might sensibly wager $15,000 to force the draw if she thought she had a good chance of responding correctly. If only one is correct, that person wins. If they are both right, they draw. If both are wrong, second place goes bankrupt and the leader wins with $10,000.
Compare that to what happens if the leader wagers $10,001 (enough to guarantee victory with a correct response) and second place wagers $5,000. All outcomes remain the same except when both are wrong. Now the leader drops to $9,999 and the person trailing previously wins with $10,000.
Sure, these are good reasons to play to draw, but I think there is something more nefarious going on. Arthur knows he is better than the contestants he has been beating. One of the easiest ways to lose as Jeopardy! champion is to play a game against someone who is better than you. So why would you want to get rid of contestants that you are better than? Creating a co-champion means that the producers will draw one less person from the contestant pool for the next game, meaning there is one less chance you will play against someone better than you. This is nefarious because it looks nice–he is allowing second place to take home thousands and thousands of dollars more than they would be able to otherwise–but really he is saying “hey, you are bad at this game, so please keep playing with me!”
In addition, his alleged kindness might even be reciprocated one day. Perhaps someone he permits a draw to will one day have the lead going into Final Jeopardy. Do you think that contestant is going to play for the win or the draw? Well, if Arthur is going to keep that person on the gravy train for match after match, I suspect that person is going to give Arthur the opportunity to draw.
It’s nefarious. Arthur’s draws could spread like some sort of vile plague.
Abstract: How do weapons inspections alter international bargaining environments? While conventional wisdom focuses on informational aspects, this paper focuses on inspections’ impact on the cost of a potential program–weapons inspectors shut down the most efficient avenues to development, forcing rising states to pursue more costly means to develop arms. To demonstrate the corresponding positive effects, this paper develops a model of negotiating over hidden weapons programs in the shadow of preventive war. If the cost of arms is large, efficient agreements are credible even if declining states cannot observe violations. However, if the cost is small, a commitment problem leads to positive probability of preventive war and costly weapons investment. Equilibrium welfare under this second outcome is mutually inferior to the equilibrium welfare of the first outcome. Consequently, both rising states and declining states benefit from weapons inspections even if those inspections cannot reveal all private information.
If you are here for the long haul, you can download the chapter on the purpose of weapons inspections here. Being that it is a later chapter from my dissertation, here is a quick version of the basic “butter-for-bombs” model:
Imagine a two period game between R(ising state) and D(declining state). In the first period, D makes an offer x to R, to which R responds by accepting, rejecting, or building weapons. Accepting locks in the proposal; R receives x and D receives 1-x for the rest of time. Rejecting locks in war payoffs; R receives p – c_R and D receives 1 – p – c_D. Building requires a cost k > 0. D responds by either preventing–locking in the war payoffs from before–or advancing to the post-shift state of the world.
In the post-shift state, D makes a second offer y to R, which R accepts or rejects. Accepting locks in the offer for the rest of time. Rejecting leads to war payoffs; R receives p’ – c_R and D receives 1 – p’ – c_D, where p’ > p. Thus, R fares better in war post-shift and D fares worse.
As usual, the actors share a common discount factor δ.
The main question is whether D can buy off R. Perhaps surprisingly, the answer is yes, and easily so. To see why, note that even if R builds, it only receives a larger portion of the pie in the later stage. Specifically, D must offer p’ – c_R to appease R and will do so, since provoking war leads to unnecessary destruction. Thus, if R ever builds, it receives p’ – c_R for the rest of time.
Now consider R’s decision whether to build in the first period. Let’s ignore the reject option, as D will never be silly enough to offer an amount that leads to unnecessary war. If R accepts x, it receives x for the rest of time. If it builds (and D does not prevent), then R pays the cost k and receives x today and p’ – c_R for the rest of time. Thus, R is willing to forgo building if:
x ≥ (1 – δ)x + δ(p’ – c_R) – (1 – δ)k
Solving for x yields:
x ≥ p’ – c_R – (1 – δ)k/δ
It’s a simple as that. As long as D offers at least p’ – c_R – (1 – δ)k/δ, R accepts. There is no need to build if you are already getting all of the concessions you seek. Meanwhile, D happily bribes R in this manner, as it gets to steal the surplus created by R not wasting the investment cost k.
The chapter looks at the same situation but with imperfect information–the declining state does not know whether the rising state built when it chooses whether to prevent. Things get a little hairy, but the states can still hammer out agreements most of the time.
I hope you enjoy the chapter. Feel free to shoot me a cold email with any comments you might have.
I can tell you when I began losing faith in standardized testing: August 11, 2009. That was the date of my GRE. My writing prompt was as follows:
Explain the causes of war.
Wow! This could not have been any more perfect. Here I was taking the GRE so I could go to grad school and write a dissertation on the causes of war. The College Board threw me a softball!
Then I received my score: 4.5. While not terrible, the 4.5 corresponded to the 63rd percentile. According to the College Board (roughly), more than a third of GRE takers could write my dissertation better than I could!
Maybe the essay was not that great. Maybe I am a terrible writer. Maybe I don’t understand the causes of war. The academic job market will likely be the ultimate arbiter of my abilities. But until then, the 4.5 seems silly.
_________
Years later, I came across this revealing article on standardized testing graders’ incentive structure. Many tests use some sort of consensus method. Begin by giving the test to two graders. If the marks are close, average the grades and move to the next exam. If the marks are not close, bring in a third grader and average the three grades in some pre-defined way.
Standardized testing companies are not in the business of giving correct grades–they are in the business of grading tests as quickly as possible. The potential for a third grader merely appeases a school’s desire to have some semblance of legitimacy. For the company, the third grader is a speed bump. Every test that reaches a third reader requires 50% more labor–and a non-negligible decrease in profitability for that particular test.
Realizing this problem, testing companies pay careful attention to their graders’ agreement rate. A low agreement rate is the mark of a bad employee. Supervisors might creatively limit the number of tests such an employee can grade (thus inflating the supervisor’s overall agreement rate for his or her team), while managers might fire him or her.
The testing companies deserve respect for creating mechanisms to keep employees in line with company goals. Unfortunately, those company goals do not comport to what we as consumers want out of the standardized testing scores we buy.
_________
I have loved game shows all my life. One of my earliest memories is of watching Family Feud. The game is simple: producers survey 100 people with a variety of questions. They then tally the responses. Contestants on the show must then guess which answer was most frequently given.
Note the emphasis here is on matching, not correctness. For example, suppose the prompt was “name a cause of war.” As a contestant, I would say “greed” or “irrationality” way before I said “private information” and “commitment problems.” The first two responses are terrible, terrible answers. The second two are fantastic. Yet, because your average survey taker has not read “Rationalist Explanations for War,” I would not expect many people to give sensible responses to the survey. So commitment problems would yield a smaller score than greed. In turn, I as a contestant pander to their ignorance and say the silly thing.
_________
Suppose you are a test grader. Better yet, say you are the test grader. God has endowed you with absolute authority in test grading matters. You know a 10 essay is a 10 essay and a 1 essay is a 1 essay. Whereas others struggle to see the difference, your observations are perfect.
But you are also broke and need a job. I hand you a test. You recognize it is a clear 10. What grade do you give it?
In a world of justice, your answer is 10. But in a world where you need to eat, you take a different route. Perhaps the essay did something strange, something you have never seen before–something like argue that bargaining problems cause war. You recognize that such an argument reflects scholarly consensus and would be the baseline for tenure at Stanford. But you also know that other graders will think that the argument is just plain bizarre. So you credit the writer for having decent organizational structure but not much substance and turn in a 7.
The other grader gives it a 6.5. The system counts it as a match and you do not get into trouble.
Grading systems are not grading systems–they coordination games with multiple equilibria. Like in the Family Feud, a reader should not give the grade the writer actually deserves but rather what he or she thinks other readers will give it.
But this leads to perverse equilibria. For example, if we all created the rule that essays beginning with a vowel are 10s and essays beginning with consonants are 2s, no one would want to break the system and risk the wrath of being labeled inefficient. So substance goes out the window. Graders instead look for focal points to coordinate their scores.
Those cues need not reflect anything of substance. To wit, consider the following review of a supervisor’s team:
[A] representative from a southeastern state’s Department of Education visited to check on how her state’s essays were doing. As it turned out, the answer was: not well. About 67 percent of the students were getting 2s.
That’s when the representative informed Farley that the rubric for her state’s scoring had suddenly changed.
“We can’t give this many 1s and 2s,” she told him firmly.
The scorers would not be going back to re-grade the hundreds of tests they’d already finished—there just wasn’t time. Instead, they were just going to give out more 3s.
3s magically appeared out of nowhere–partially because the testing company wanted a higher average, and partially because graders feared that giving a 1 or 2 would result in a mismatch and disciplining from the supervisor.
The article is full of other lovely anecdotes and worth the read. And it is also terrifying to think about.
_________
In retrospect, I should not have written about how bargaining problems cause war. From the point of view of a grader, it is just too bizarre. I deserve my 4.5 for not properly playing the game.
(I suppose three years of grad school has made me more cynical about life. Perhaps a better subtitle for this article is “How I Learned to Stop Worrying and Love Pandering.”)
Of course, that is precisely the problem. The incentive system for grading is perverse and rewards students for writing safe–and not particularly insightful–essays. In contrast, the academic job market rewards the opposite approach. Write a dissertation that has been done a thousand times before, and you won’t find employment. Do something revolutionary, and have your pick at the top jobs.
The test companies do not have final say over the method of standardized testing grading. We do. It’s time we demand change in the system.
In standard bargaining situations, both parties understand the fundamentals of the agreement. For example, if I offer you a $20 per hour wage, then I will pay you $20 per hour; if I propose a 1% sales tax increase, then sales tax will increase by 1%. But not all such deals are evident. Senate confirmation of judicial nominees is particularly troublesome—the President has a much better idea of the true nominee’s ideology than the Senate does. Indeed, as the Senate votes to confirm or reject, the Senate may very well be unsure what it is buying.
This situation is the center of a new working paper from Maya Sen and myself. We develop a formal model of the interaction between the President and the Senate during the judicial nomination process. At first thought, it might seem as though the President benefits from the lack of information by occasionally sneaking in extremist justices the Senate would otherwise reject. However, our main results show that this lack of information ultimately harms both parties.
To unravel the logic, suppose the President could nominate a moderate or an extremist. Now imagine that the Senate is ideologically opposed, so it only wants to confirm the moderate. The choice to reject is not so simple, though, because the Senate cannot directly observe the nominee’s type but rather must make inferences based on a noisy signal. Specifically, the Senate receives a signal with probability p if the President chooses an extremist. (This signal might come from the media uncovering a “smoking gun” document.) The President suffers a reputation cost if he is caught in this manner. If the President selects a moderate, the Senate receives no signal at all. Thus, upon not receiving a signal, the Senate cannot be sure whether the President nominated a moderate or extremist.
With those dynamics in mind, consider how the President acts when the signal is weak. Can he only nominate an extremist? No–the Senate would obviously always reject regardless of its signal. Can he only nominate a moderate? No–the Senate would respond by confirming the nominee despite the lack of a signal, but the President could then gamble by selecting an extremist and hoping that the weak signal works in his favor. As such, the President must mix between nominating a moderate and nominating an extremist.
Similarly, the Senate must mix as well. If it were to always confirm, the President would nominate extremists exclusively, but that cannot be sustainable for the reasons outlined above. If the Senate were to always reject, the President would only nominate moderates to avoid smoking guns. But then the Senate could confirm the moderates it was seeking.
Thus, both parties mix. Put differently, the President sometimes bluffs and sometimes does not; the Senate sometimes calls what it perceives as bluffs and sometimes lets them go.
These devious behaviors have an unfortunate welfare implication–both parties are worse off than if they could agree to appoint a moderate. Since the Senate mixes, it must be indifferent between accepting and rejecting. The indifference condition means that the Senate receives its rejection payoff in expectation, which is worse than if it could induce the President to appoint a moderate. Meanwhile, the President is also mixing, so he must be indifferent between nominating a moderate and nominating an extremist. But whenever he nominates a moderate, the Senate sometimes rejects. This also leaves the President in worse position than if he could credibly commit to appointing moderates exclusively.
Further, we show that the President and Senate can only benefit from more information about judicial nominees when they are ideologically opposed. And yet there seems to be little serious effort to change the current charade of judicial nominee hearings. (During Clearance Thomas’s hearing, when asked whether Roe v. Wade was correctly decided, he unconvincingly replied that he did not have an opinion “one way or the other.”) Why not?
The remainder of our paper investigates this question. We point to the potential benefits of keeping nominee ideology secret when the Senate is ideologically aligned with the President. Under these conditions, the President can nominate extremists and still induce the Senate to accept. Keeping the process quiet allows the President to nominate such extremists without worrying about suffering reputation costs as a result. Consequently, the current system persists.
Although our focus is on judicial nominations, the same obstacles are likely present in other nominations processes. And coming from an IR background, I have been thinking about similar situations in interstate bargaining. In any case, please check out the paper if you have a chance. We welcome your comments on it.
Two years ago today, I published the first incarnation of Game Theory 101: The Complete Textbook. (It was incomplete back then, heh.) Every summer, I like to go through it and make changes where I can. This time around, I decided to add a new lesson on games with infinite strategy spaces, like Hotelling’s game, second price auctions, and Cournot competition. I have correspondingly added some content to the MOOC version. Videos below.
Initially, I was hesitant to add more material to the textbook because Amazon’s fee increases as the file size of the book increases. Yet, the size of the textbook shrunk because I cut down on unnecessarily wordy sentences. (Switching “is greater than” to “beats” probably chopped off 300 words from the book.)
The optimistic interpretation: Readers now learn more while reading less!
The pessimistic interpretation: I really, really need to work on writing shorter sentences.
I was watching the NBA Finals last night. While the series has been good, watching professional basketball requires a certain tolerance for flopping–i.e., players pretending like they got hit by a freight train when in reality the defender barely made incidental contact. Observe LeBron James in action:
And that’s just from this postseason!
No one likes flopping, but it is not going away anytime soon. This post explains the rationality of flopping. The logic is as you might think–players flop to dupe officials into mistakenly calling fouls. There is a surprising result, however. When flopping optimally, “good” officiating becomes impossible–referees are completely helpless in deciding whether to call a foul. Worse for the integrity of the game, a flopper’s actions force referees to occasionally ignore legitimate fouls.
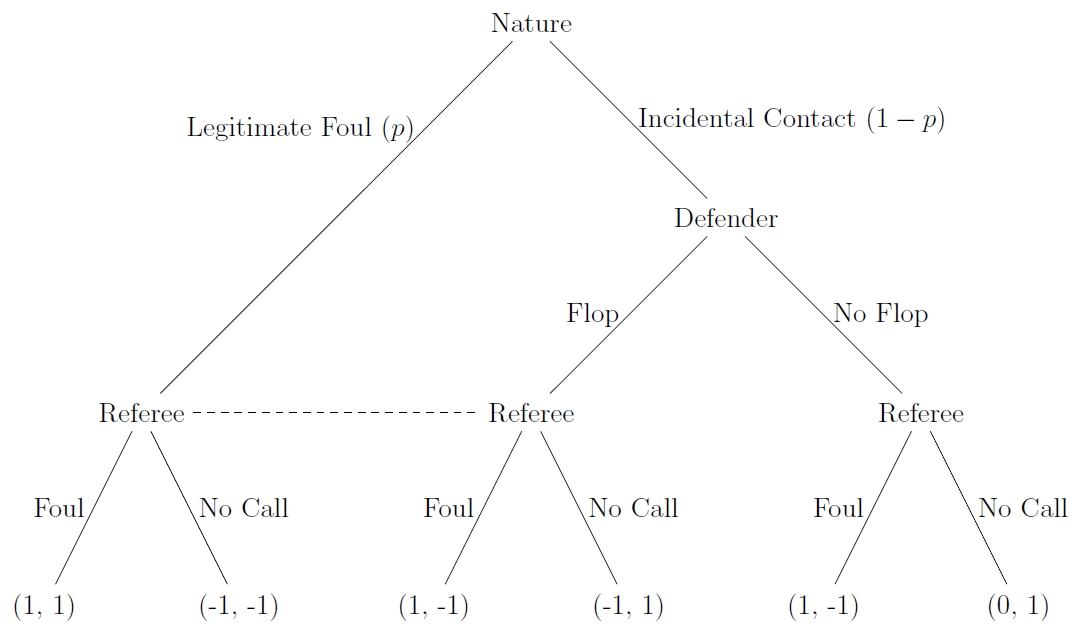
The Model
This being a blog post, let’s construct a simple model of flopping. (See figure below.) The game begins with an opponent barreling into a defender. Nature sends a noisy signal to the official whether contact was foul worthy or not. If it is truly a foul, the defender falls to the ground without a strategic decision. If it is not a foul, the player must decide whether to flop or not.
The referee makes two observations. First, he receives the noisy signal. With probability p, he believes it was a hard foul; with probability 1-p, it was not. He also observes whether the defender fell to the ground. Since the defender cannot keep standing if the offensive player commits a hard foul, the referee knows with certainty that the play was clean if the defender remains standing. However, if the player falls, the referee must make an inference whether the play was a foul.
Payoffs are as follows. The referee only cares about making the right call; he receives 1 if he is correct and -1 if he is incorrect. The player receives 1 if the referee calls a foul, 0 if he does not flop and the referee does not call a foul, and -1 if he flops and the referee does not call a foul. Put differently, the defender’s best outcome is what minimizes the offense’s chance at scoring while his worst outcome is what maximizes the offense’s chance.
(click image to enlarge)
Equilibria
Since legitimately fouled defenders have no strategic choices, we only have to solve for the non-fouled defender’s action. Therefore, throughout this proof, “defender” means a defender who was not fouled. (Rare exceptions to this will be obvious.)
We break down the parameter space into three cases:
For p = 0 Flopping does not work, since the referee knows no foul took place. This is why players don’t randomly fall to the ground when the nearest opponent is ten feet away from them.
For p > 1/2 Note the the referee will call a foul if he believes that the probability the play was a foul is greater than 1/2. Thus, if the defender flops, he knows the referee will call a foul. As such, the defender always flops, and the referee calls a foul. This is intuitive: on plays that look a lot like a foul, defenders will embellish the contact regardless of how hard they are hit.
For 0 < p < 1/2 Because mixing probabilities are messy, I will appeal to Nash’s theorem to prove that both the defender and referee mix in equilibrium. Recall that Nash’s theorem says that an equilibrium exists for all finite games. Therefore, we can show both players mix by proving that neither can play a pure strategy in equilibrium. (In other words, we expect players to sometimes flop and sometimes not to, while the referees to sometimes call a foul and sometimes not to when they aren’t sure.)
First, can the defender flop as a pure strategy? If he does, the referee’s best response would be to not call a foul, as the referee believes the probability a foul occurred is less than 1/2. But given that the referee is not calling a foul, the defender should deviate to not flopping, since he will not get the call anyway.
Second, can the defender not flop as a pure strategy? If he does, the referee’s best response is to call a foul if he observes the defender falling, as he knows that the play was a legitimate foul. But this means the defender would want to deviate to flopping, since he knows he will get the foul called. This exhausts the defender’s pure strategies, so the defender must be mixing in equilibrium.
Third, can the referee call a foul as a pure strategy? If he does, the defender’s best response is to flop. But then the referee would not want to call a foul, since his belief that the play was actually a foul is less than 1/2.
Fourth, can the referee not call a foul as a pure strategy? If he does, the defender’s best response is to not flop. But this means the referee should call a foul upon observing the defender fall, as he believes the only way this could occur is if the foul was legitimate. This exhausts the referee’s pure strategies, so the referee must mix in equilibrium.
Strategically, these parameters are the most interesting. In equilibrium, the defender sometimes bluffs (by flopping) and sometimes does not. Upon observing a fall, the referee sometimes ignores what he perceives might be a flop and sometimes makes the call.
The real loser is the legitimately fouled defender. He can’t do anything to keep himself from falling over, yet sometimes the referee does not make the call. Why? The referee can’t know for sure whether the foul was legitimate or not and must protect against floppers.
While this seems unfortunate, be glad the referees act strategically in this way–the alternative would be that defenders would always flop regardless of how incidental the contact is and the referees would always give them the benefit of the doubt.
Conclusion
One of game theory’s strengths is drawing connections between two different situations. Although this post centered on flopping in the NBA, note that the model was not specific to basketball. The interaction could have very well described other sports–particularly soccer. As long as fouls provide defenders with benefits, there will always be floppers waiting to exploit the referee’s information discrepancy.
Postscript
If I ever expand my game theory textbook to cover Bayesian games, I think I will include this one. This also makes decent fodder when random people ask “what can game theory do for us?”
The Walking Dead is cable’s most successful TV show, ever. I’m writing this after “Home,” and I’m going to assume you know what is going on by and large.
Here’s what’s important. As far as we care, there are only two groups of humans left alive. One, the good guys, have fortified themselves inside an abandon jail. The other lives in a walled town called Woodbury. They became aware of each other a few episodes ago, and they have various reasons to dislike each other.
War appears likely and will be devastating to both parties, likely leaving them in a position worse than if they pretended the other simply did not exist. For example, in “Home,” the Woodbury group packs a courier van full of zombies, breaches the jail’s walls, and opens the van for an undead delivery. Now a bunch of flesh-eaters are wandering around the previously secure prison.
Meanwhile, the jail’s de facto leader went on a mysterious shopping spree and came back with a truck full of unknown supplies. I suspect next episode will feature the jail group bombing a hole in Woodbury’s city walls.
All this leads to an important question: why can’t they all just get along? It’s the end of the world for goodness sake!
As someone who studies war, I am sympathetic to the problem. Woodbury and the jail group are capable of imposing great costs on one another merely by allowing zombies to penetrate the other’s camp. The situation seems ripe for a peaceful settlement, since there appear to be agreements both parties prefer to continued conflict.
This is the crux of James Fearon’s Rationalist Explanations for War, one of the most important articles in international relations in the last twenty years. Fearon shows that as long as war is costly and the sides have a rough understanding of how war will play out, then both parties should be willing to sit down at the bargaining table and negotiate a settlement.
However, Fearon notes that first strike advantages kill the attractiveness of such bargains. From the article:
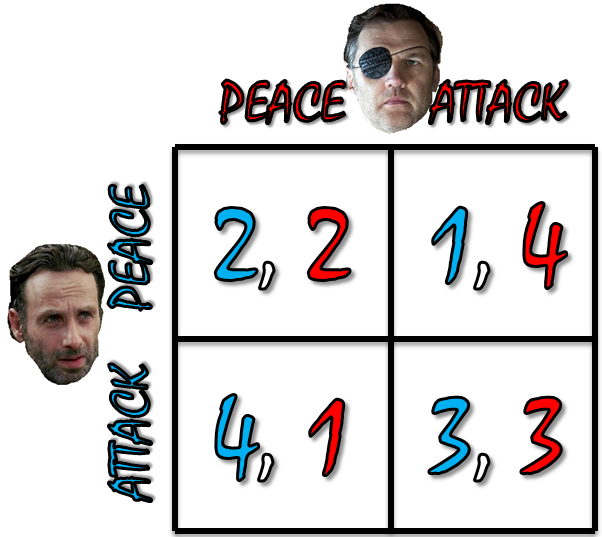
Consider the problem faced by two gunslingers with the following preferences. Each would most prefer to kill the other by stealth, facing no risk of retaliation, but each prefers that both live in peace to a gunfight in which each risks death. There is a bargain here that both sides prefer to “war”…[but] given their preferences, neither person can credibly commit not to defect from the bargain by trying to shoot the other in the back.
The jail birds and Woodbury are in a similar position:
This is a prisoner’s dilemma.[1] Both parties prefer peace to mutual war. But peace is unsustainable because, given that I believe you are going to act peacefully, I prefer taking advantage of you and attacking. This leads to continued conflict until one side has been destroyed (or, in this case, eaten by zombies), leaving both worse off. We call this preemptive war, as the sides are attempting to preempt the other’s attack.
In the real world, countries have tried to reduce the attractiveness of a first strike by creating demilitarized zones between disputed territory, like the one in Korea. But such buffers require manpower to patrol to verify the other party’s compliance. Unfortunately, the zombie apocalypse has left the world short of people–Woodbury has fewer than a hundred, and the jail birds have fewer than ten. As a result, I believe we be witnessing preemptive war for the rest of this season.
[1] Get it? They live in a jail, and they are in a prisoner’s dilemma![2]